There are two main issues while casting an object dynamically.
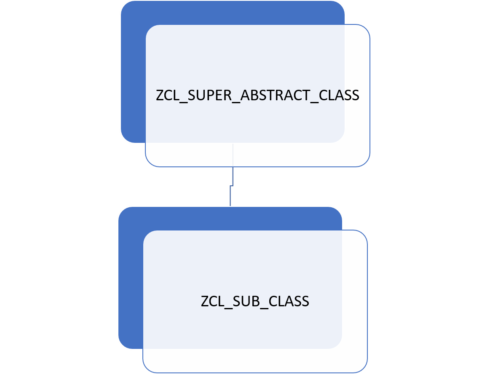
If the target object is an abstract super class, then we cannot use CREATE OBJECT lr_super_abstract TYPE REF TO (lv_super_abstract_class_name). Here lv_super_abstract_class name is ‘ZCL_SUPER_ABSTRACT_CLASS’
We cannot use field symbol to do this object casting dynamically.
METHODS object_casting IMPORTING ir_zcl_sub_class TYPE REF TO zcl_sub_class.
METHOD object_casting.
DATA lv_super_abstract_class_name TYPE STRING VALUE ‘ZCL_SUPER_ABSTRACT_CLASS’.
DATA lr_super_abstract_class TYPE REF TO DATA.
CREATE DATA lr_super_abstract_class TYPE REF TO (lv_super_abstract_class_name).
lr_super_abstract_class->* ?= ir_zcl_sub_class.
WRITE:/ ‘ our super abstract class is casted dynamically and its object instance is successfully stored in the reference variable lr_super_abstract_class’
ENDMETHOD.
Note: please don’t use ->* to use the instance object. instance use directly lr_super_abstract_class.
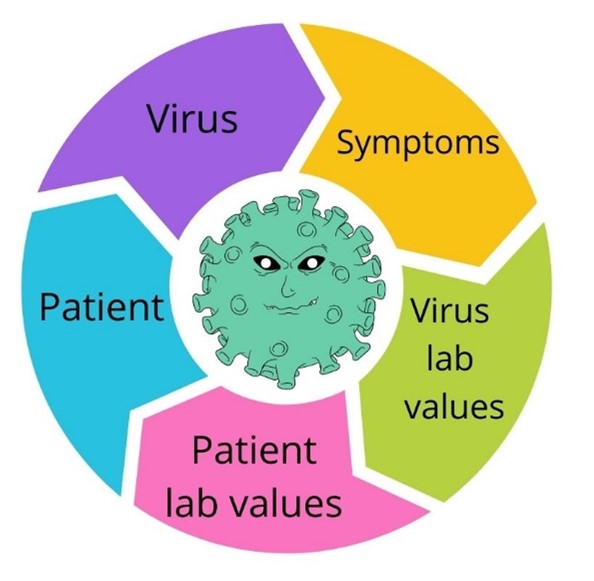
This Corona test application is used to test the critical values of the patient. With the help of this application, one can figure out if the patient has Corona Virus. The critical laboratory parameters of the Corona Virus are controlled using the Administrator user interface. The virus details can also be stored in this application. The corona virus symptoms and the patient symptoms are compared in this program. The patient personal details are also entered in this Application.
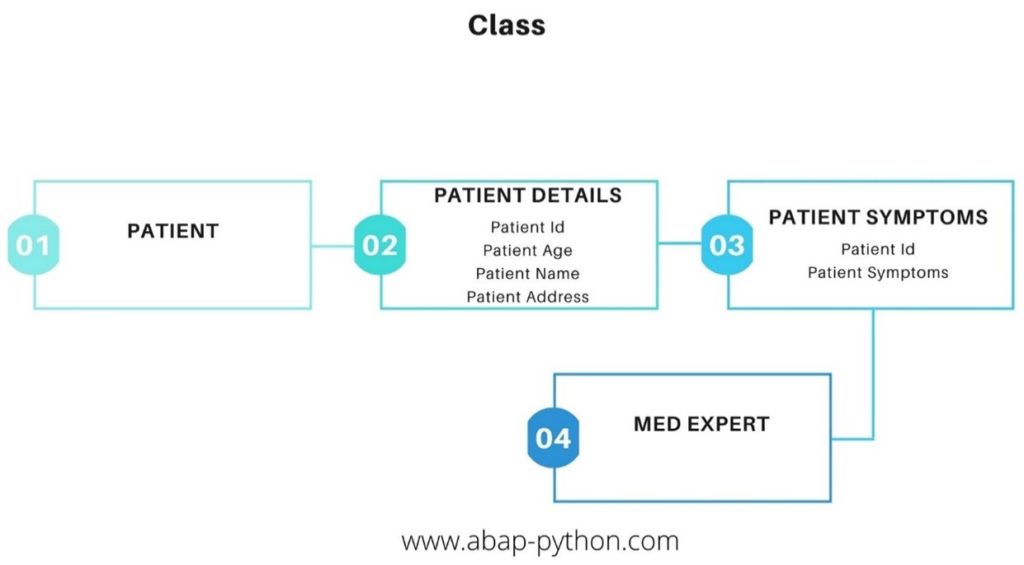
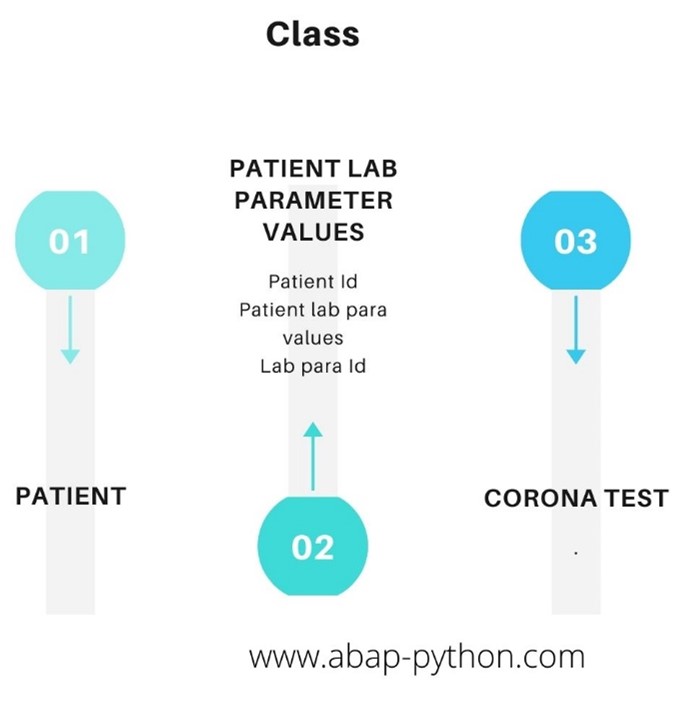
The first and foremost step in building any application is understanding the type of data involved in the program. The corona virus must be differentiated from other types of virus. Each virus is unique, and it needs to be differentiated using an Id and description. The critical Laboratory parameters of the corona virus in the patient are WBC values, … These parameters must be uniquely identified using an Id, name. Its value determines whether the patient has Corona virus. The lower limit and higher limit of the Laboratory parameters are critical in detecting the corona virus. The symptoms of the corona virus are tracked in the symptom Id and description.
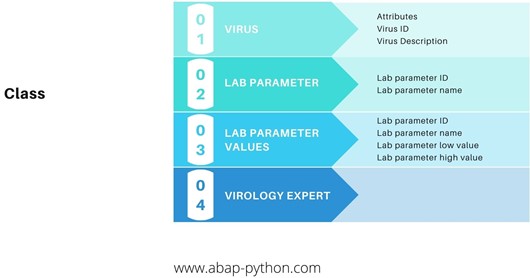
It can be uniquely identified using Id number. So every main entity here has an Id. For example, the entities such as virus, symptom, patient has an unique Id. The following table shows the properties of each entity.
Virus
Symptom
Patient
Virus lab parameter
Virus Id Virus Description
Symptom Id Symptom Description
Patient Id Patient name Patient age Patient address
Parameter Id Parameter name Parameter Critical values
We have successfully identified the critical data in our corona test application. Now we have to Build the ABAP Data Dictionary using the critical data.
Interface: One of the key concepts which can be considered as the Skeleton of the object oriented model. Let us consider the following interfaces to implement the corona test application.
ZIF_VIR_DETAILS
ZIF_LAB_ATTRIBUTE_NAME
ZIF_LAB_ATTRIBUTE_VALUE
ZIF_SYMPTOMS
ZIF_PATIENT
Now, Let us look at the definition of each Interfaces.
INTERFACE zif_vir_details
PUBLIC.
METHODS set_vir_details
IMPORTING i_virus_id TYPE zde_virus_id
i_virus_desc TYPE zde_virus_desc.
METHODS get_vir_details
IMPORTING i_virus_id TYPE zde_virus_id
EXPORTING e_virus_desc TYPE zde_virus_desc.
ENDINTERFACE.
INTERFACE zif_lab_attribute_name
PUBLIC .
METHODS set_attribute_name
IMPORTING i_lab_attribute_name TYPE zde_parameter_name
i_lab_attribute_id TYPE zde_parameter_id
i_virus_id TYPE zde_virus_id.
METHODS get_attribute_name
IMPORTING i_lab_attribute_id TYPE zde_parameter_id
i_virus_id TYPE zde_virus_id
EXPORTING e_lab_attribute_name TYPE zde_paramete_name.
ENDINTERFACE.
INTERFACE zif_lab_attribute_value
PUBLIC.
METHODS set_lab_attribute_value
IMPORTING i_lab_attribute_id TYPE zde_parameter_id
i_virus_id TYPE zde_virus_id
i_lab_para_low_value TYPE ZDE_lab_para_low_value
i_lab_para_high_value TYPE ZDE_lab_para_high_value.
METHODS get_lab_attribute_value
IMPORTING i_lab_attribute_id TYPE zde_parameter_id
EXPORTING e_lab_para_value TYPE int4
ENDINTERFACE.
INTERFACE ZIF_SYMPTOMS
PUBLIC.
METHODS set_symptoms
IMPORTING i_symptom_id TYPE zde_symptom_id
i_symptom_desc TYPE zde_symptom_desc.
METHODS get_symptoms.
EXPORTING et_symptoms TYPE ztt_symptom_ty.
ENDINTERFACE.
INTERFACE zif_patient
PUBLIC.
METHODS set_patient_details
IMPORTING i_patient_id TYPE zde_patient_id
i_patient_name TYPE zde_patient_name
i_patient_age TYPE num02
i_patient_address TYPE zde_patient_address.
METHODS get_patient_details
IMPORTING i_patient_id TYPE zde_patient_id
EXPORTING e_patient_name TYPE zde_patient_name
e_patient_age TYPE num02
e_patient_address TYPE zde_patient_address.
METHODS set_patient_symptoms
IMPORTING i_symptom_desc TYPE zde_symptom_desc
i_patient_id TYPE zde_patient_id.
METHODS get_patient_symptoms.
IMPORTING i_patient_id TYPE zde_patient_id
EXPORTING et_symptom_desc TYPE ztt_symptom_desc.
METHODS set_patient_lab para_values.
IMPORTING i_patient_id TYPE zde_patient_id
i_lab_para_id TYPE zde_parameter_id
i_lab_para_value TYPE int4.
METHODS get_patient_lab_para_values.
IMPORTING i_patient_id TYPE zde_patient_id
i_lab_para_id TYPE zde_parameter_id
EXPORTING e_lab_para_value TYPE int4.
ENDINTERFACE.
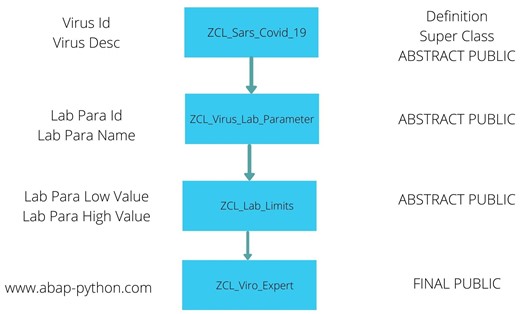
Now we have discussed about the data, Data tables, Object branches, skeleton of the system (Interface).
The front end helps us to understand the whole process easily. So lets begin with the user interface for the virology expert team.
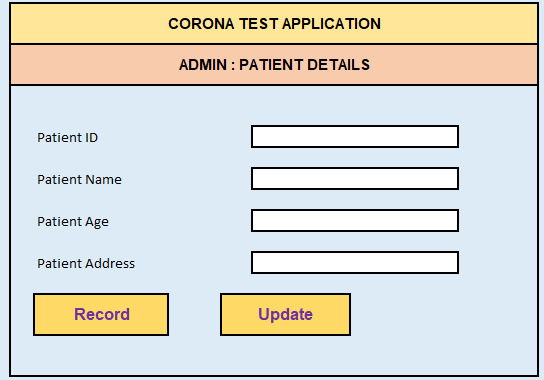
User Interface for Virology expert Team
Figure 1 Admin User Interface
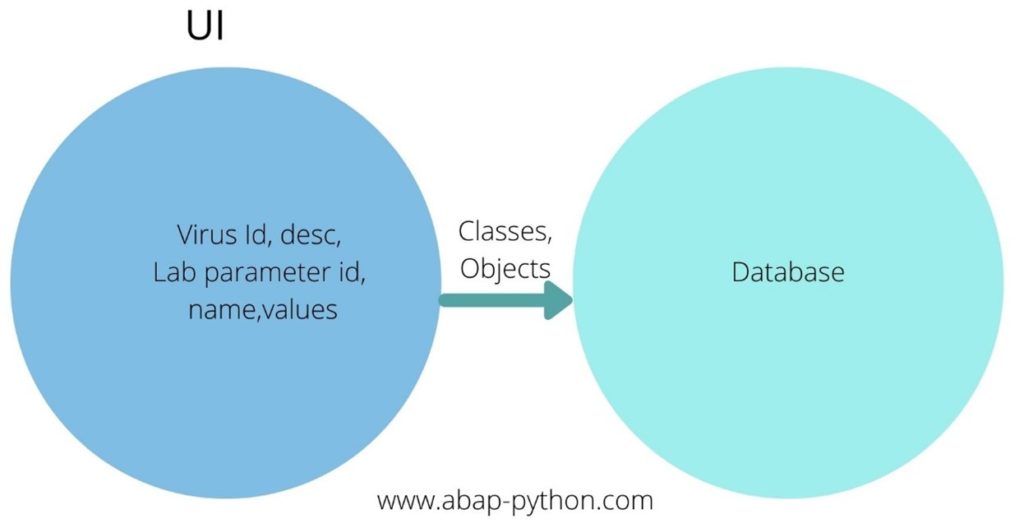
The user interface depicts the input elements of the virus information systems. The data which is entered in these textboxes, must be stored in the Database.
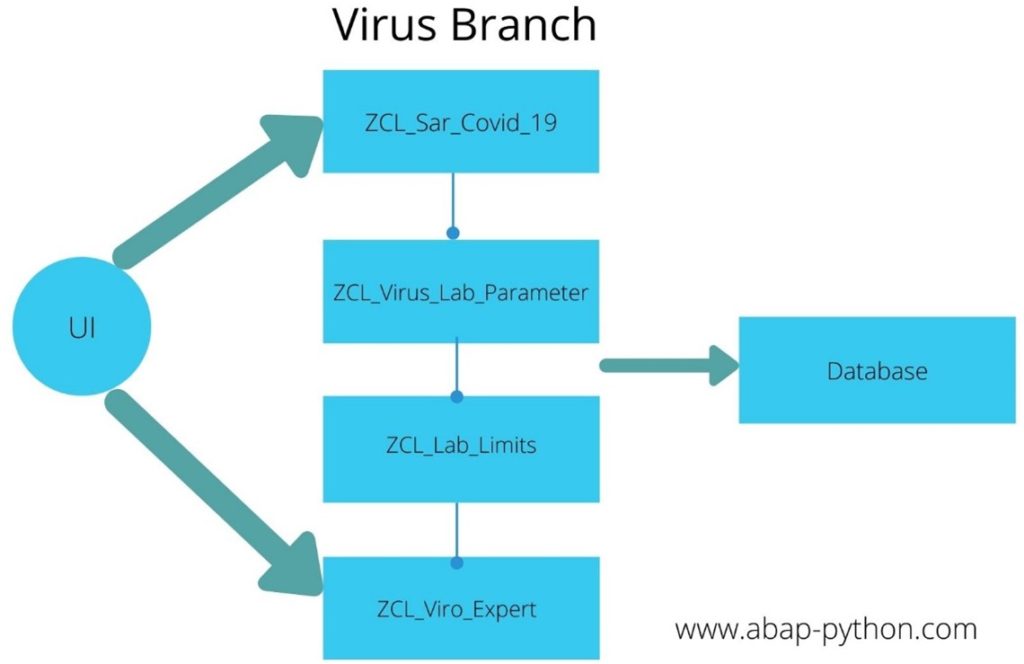
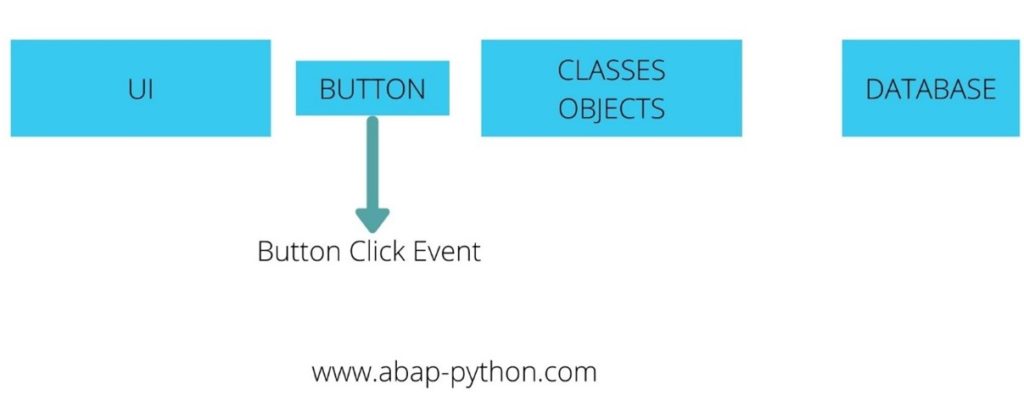
The data from the user interface elements are passed through the classes and objects. These Sar_Covid 19, virus lab parameters, lab limits objects carry the data from the user interface and insert the data into the database. The very next step would be to create objects. Now we will investigate the creation of these classes. We discussed about the different object oriented branches in the beginning. Now we will look in detail about the code for each of these branches.
Picture below depicts the different classes between the UI and Database.
The developed Corona test application is used to test the Critical Medical parameters of the patient. The Corona Symptoms are compared to the patient symptoms. The corona test is evaluated based on the values of the laboratory parameters. The different Laboratory parameter can also be administered centrally in the system.
Required Elements in creating the classifications.
Structure – It includes the details such as variant id, variant name, amino acid changes, potential, spread.
Interface Definition – The variant details of the sars covid 2 will be handled here.
Abstract super class definition – This class implements the interface. The constructor is used to set the details of the variant.
Sars covid variant 1 sub class definition – It inherits the Abstract super class definition.
Report creation – It creates the instances of the sars covid 2 variant.
Structure definition:
Before creating the structure, let’s define the Data elements for the fields of the structure. All the fields of the structure can be defined with string type of data element. The variant can be identified with the key element as variant id.Let’s create a data element as ‚ZDE_Variant_string‘ with string type domain. Another Data element ZDE_VARIANT_ID with int4 type domain.
Let’s define the structure name ‚ZSVARIANT_DETAILS‘ with description
The fields of the structure are created as shown below.
Field = Variant_id , Data element = ZDE_VARIANT_ID, Domain type INT4
Field = Variant_name, Data element = ZDE_VARIANT_STRING, Domain type STRING
Field = amino acid changes, Data element = ZDE_VARIANT_STRING, Domain type STRING
Field = Potential, Data element = ZDE_VARIANT_STRING, Domain type STRING
Field = Spread, Data element = ZDE_VARIANT_STRING, Domain type STRING
Interface definition:
INTERFACE zif_sars_covid_2_variants
PUBLIC.
METHODS get_variant_details EXPORTING es_variant_details TYPE zsvariant_details.
ENDINTERFACE.
Abstract super class definition and implementation:
CLASS zcl_sars_covid_2 DEFINITION.
PUBLIC
ABSTRACT
CREATE PUBLIC.
PUBLIC SECTION.
INTERFACES zif_sars_covid_2_variants.
METHODS constructor IMPORTING is_variant_details TYPE zsvariant_details.
The next decade will see the emergence of strange new job “data trash engineer” will arrive to replace those made obsolete by robots and automation, but the report’s authors warn that they’ll require society to handle a big shift in education and training. There has been plenty of fear in recent years about the rise of artificial intelligence, with forecasts suggesting that anything from 33 per cent to 50 per cent of certain jobs at risk of being taken over by machines.
In the report, it outlines the professions that will appear in the future as society adapts to a more automated and highly digitised world, with many of them reading like something from a sci-fi film or dystopian novel. With names like “head of machine personality design” and “flying car developer,” some of them are fairly self-explanatory and already semi-familiar, yet others suggest that the future will be a very strange place indeed.
Data Trash Engineer
Summary:
The theory behind junk data is often wrong, and we need to fix it. Data that has not been used by anyone in the past 12 months, has no foreseeable use as initially imagined, and isn’t necessary for regulatory purposes, can still be turned into insights. Just like food waste is a carbon that can be used to produce green energy, data waste is still meaningful if cleaned.
We’re seeking data trash engineers who can identify unused data in our organization, clean that data and feed it into machine-learning algorithms to find hidden insights by not only increasing how much data is collected, but also improving the data quality.
In the end, the goal of the data trash engineer is to transform data from trash to treasure. The possibilities are endless, and we expect the employee in this role to originate award-winning ideas.
What it takes to become a Data Trash Engineer?
In today’s business world, we often struggle to manage the ever-expanding volume of data around us, while also ensuring the quality of that data. As a result, we often end up labelling piles of data as waste if it hasn’t been used in the last 12 months. However, if we mine, refine and distribute it, data trash can be profitable, and the return on investment can be significant.
As a key member of a fast-paced, high-performing and highly-visible data analytics team, the data trash engineer will have the opportunity to use quantitative skills and develop well-rounded business insights by working across various functions on impactful, business-focused projects.
In this role, you’ll apply analytical rigor and statistical methods to data trash in order to guide decision-making, product development and strategic initiatives. This will be done by creating a “data trash nutrition labelling” system that will rate the quality of waste datasets and manage the “data-growth-data-trash” ratio.
For instance, if we’re expecting 30% annual growth in data over the next 12 months, the data trash engineer will ensure 30% of the data labelled as trash is cleaned and translated into key business decisions. In the end, this role will help us fix the data trash problem by establishing a ”trash-to-treasure” data supply chain.
What exactly Data Trash Engineers do?
Create a data trash nutrition labelling system to rate the quality of each dataset. Perform end-to-end analyses that include business requirement specifications, data cleaning, analyzing, modelling, validating and facilitating gradual improvements.
Become a champion of the “trash-to-treasure” innovation program by helping business teams find new opportunities, enhance customer interactions and uncover new business models. Review, analyze and share results to guide improvements, decision-making and program optimizations.
Design AI test experiments that focus on enhancing customer experiences of our offerings, services and programs, as well as offer consultation and closely monitor experiment execution. The data trash engineer will ensure an uninterrupted supply of clean data is available for AI technologies to deliver the required results.
Participate in the planning and strategy of key business projects by making business recommendations with effective presentations at multiple levels of stakeholders through visually compelling analytical results from the trash-to-treasure program.
Drive collaboration and partnership with other data teams to ensure customer success.
Partner closely with our legal teams to ensure we’re treating all customer data to comply with appropriate confidentiality and usage.
“The goal of the data trash engineer is to transform data from trash to treasure. The possibilities are endless, and we expect the employee in this role to originate award-winning ideas”.
SKILLS & QUALIFICATIONS:
A master’s degree in a quantitative discipline (e.g., statistics, computer science, quantitative psychology, applied mathematics).
Three to five years of experience with various data analysis tools, data mining tools and statistical packages.
Experience working on big data and machine learning technologies, such as Azure Cosmos DB, TLC, Azure ML, Cortana Analytics, R, Python and SQL.
Proficiency with analytical tools (R, SAS, Matlab, Python or Stata).
Development experience in at least one scripting language, such as Python, Java, C, C++, Ruby or Perl.
Solid interpersonal, cross-organizational collaboration capabilities, as well as written, verbal and visual communication skills to present complex analytical results concisely and effectively.
Experience developing data visualization offerings and dashboards.
Conclusion:
So far, we have learned what is Data Trash Engineering, what they do and how to become one by satisfying skills and qualifications.
In this blog, we will see about how to connect a database to python using PyCharm IDE.
Here we are going to connect mysql database to python. In the similar fashion we can connect any database software to python.
Here are the pre-requisite needed for establishing connection between python and mysql or any database
PRE-REQUISITE:
Adding database plugin in Pycharm
Install mysql-connector packages
Adding database Plugin:
Database plugin supports addition of packages to support the connection between database and python.Below are the steps to add the database plugin.
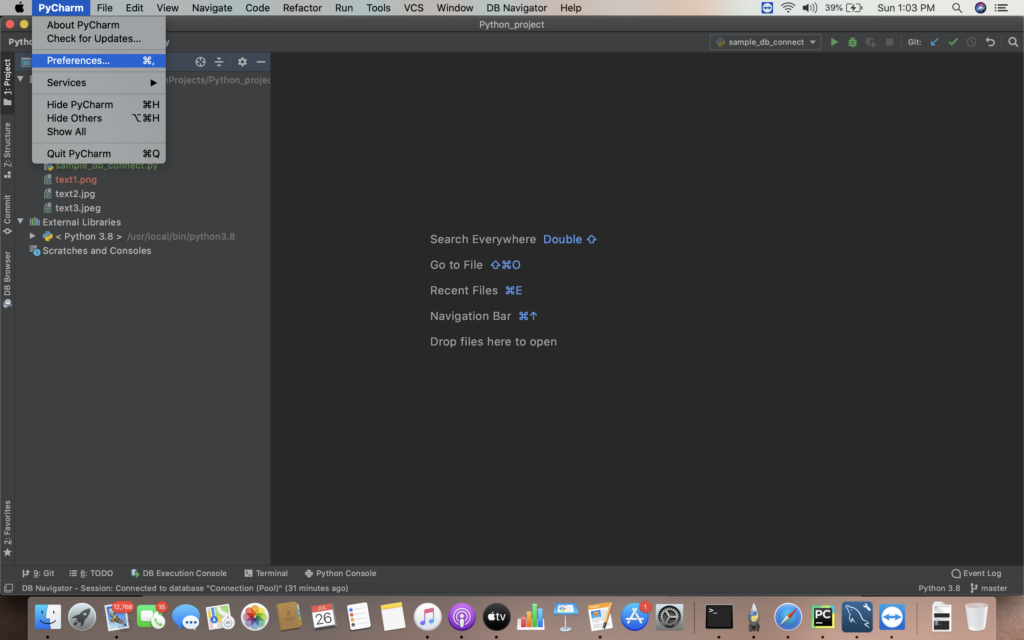
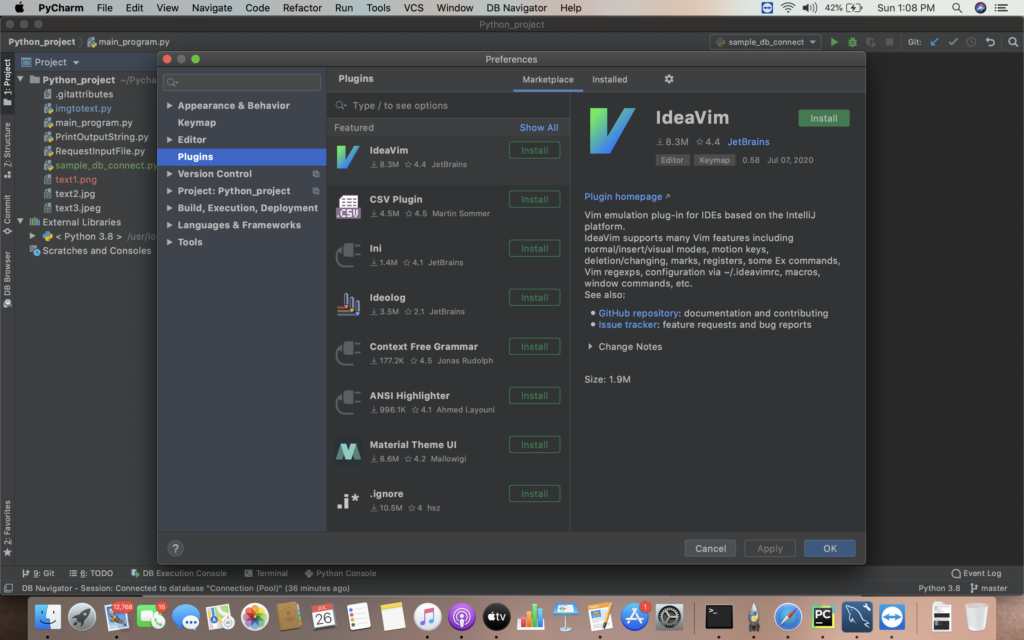
i) Select PyCharm-> Preferences or select Settings options from the IDE
ii) Select Plugins sections on the left pane of pop up dialog box.The list of plugins available from Market place will be displayed like csv , UI themes etc. As per our needs we can add the appropriate plugins.
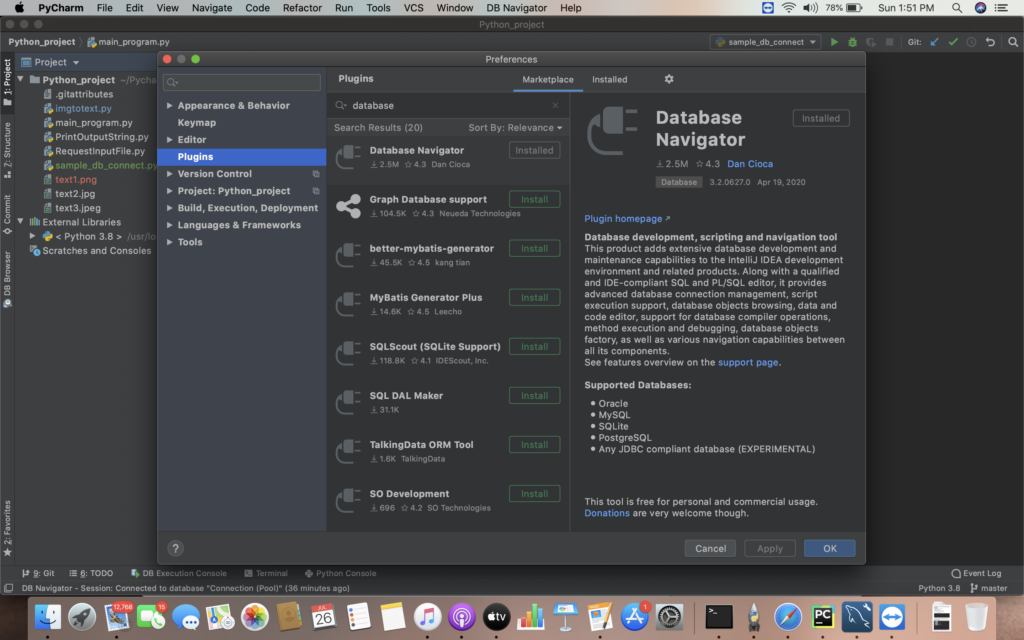
iii) Type database in search box and install the database navigator plugin.
Installing MySQL Python connector packages:
MySql connector packages need to be installed to establish connection between mysql and python. Follow the below steps to install the same using Pycharm.
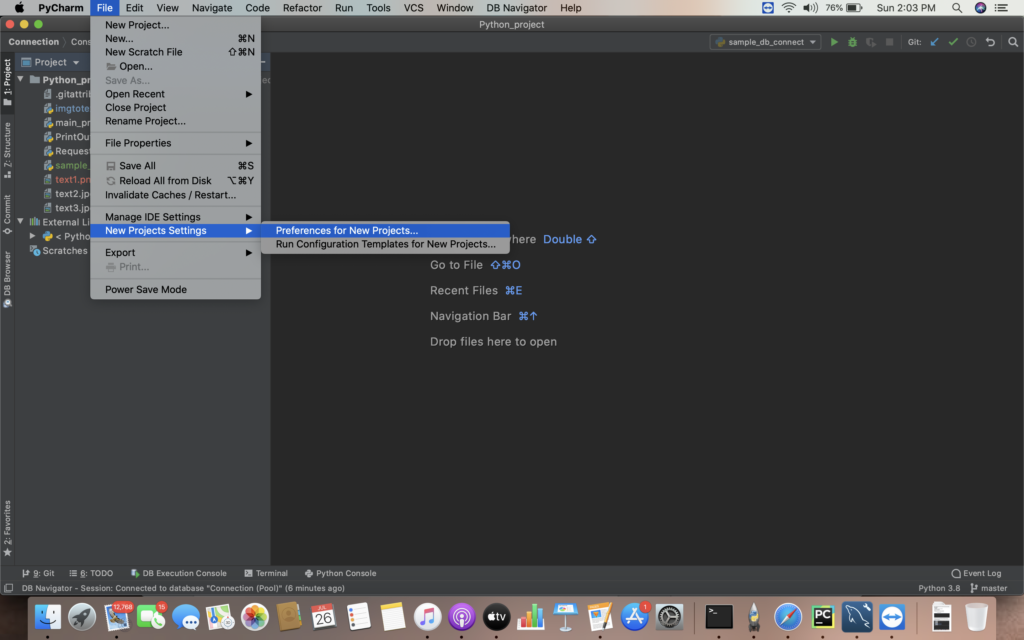
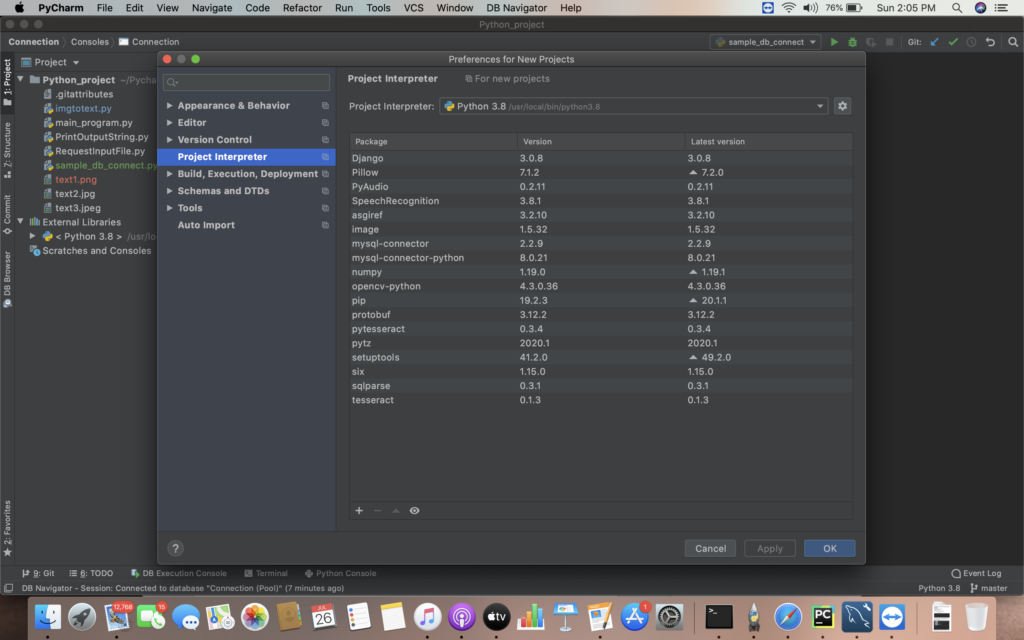
i) Go to File -> New Preferences of the project. Select Project Interpreter to add the package.
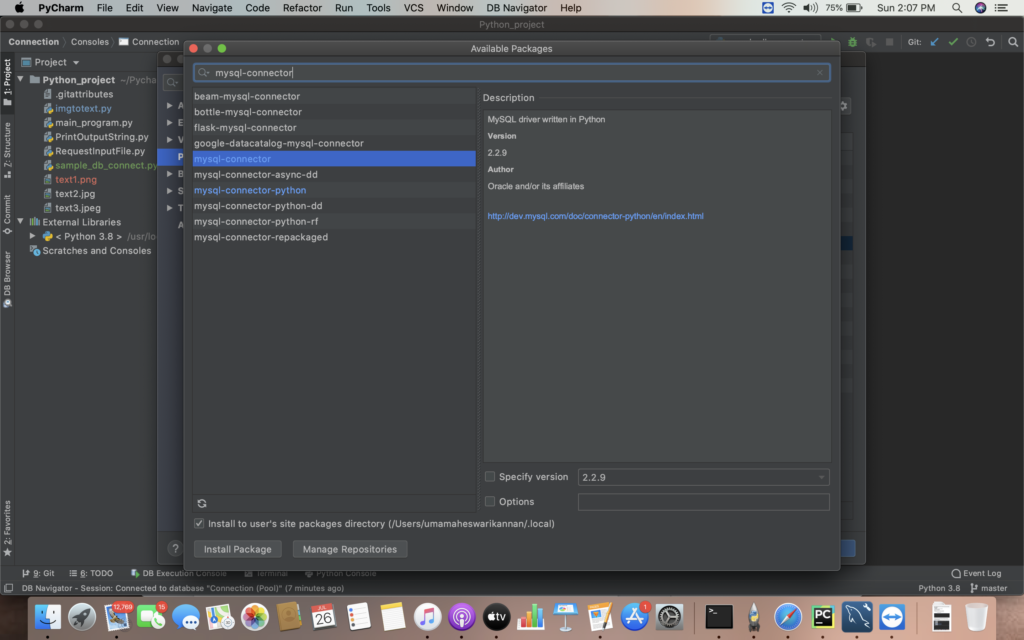
ii) Select the “+” icon to install the package. Search the mysql python connector packages and install them.
iii)Install mysql-connector and mysql-connector-python packages.
Adding new connection to connect MySQL Database
This step is essential to setup a connection to access the mysql database from python.
In this process we will need the database details we are going to connect like hostname, port, username and password.
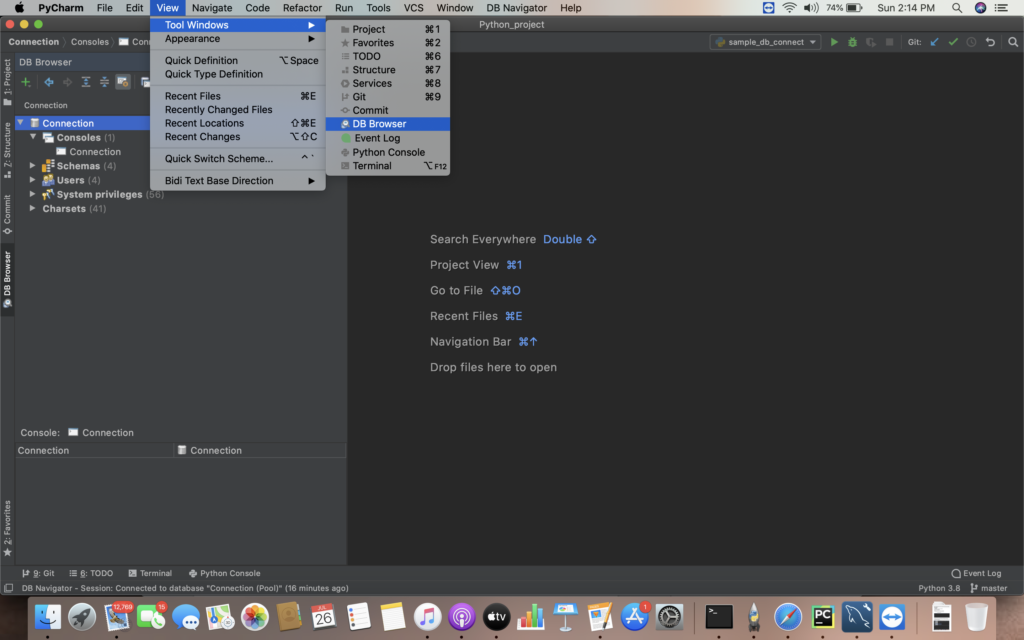
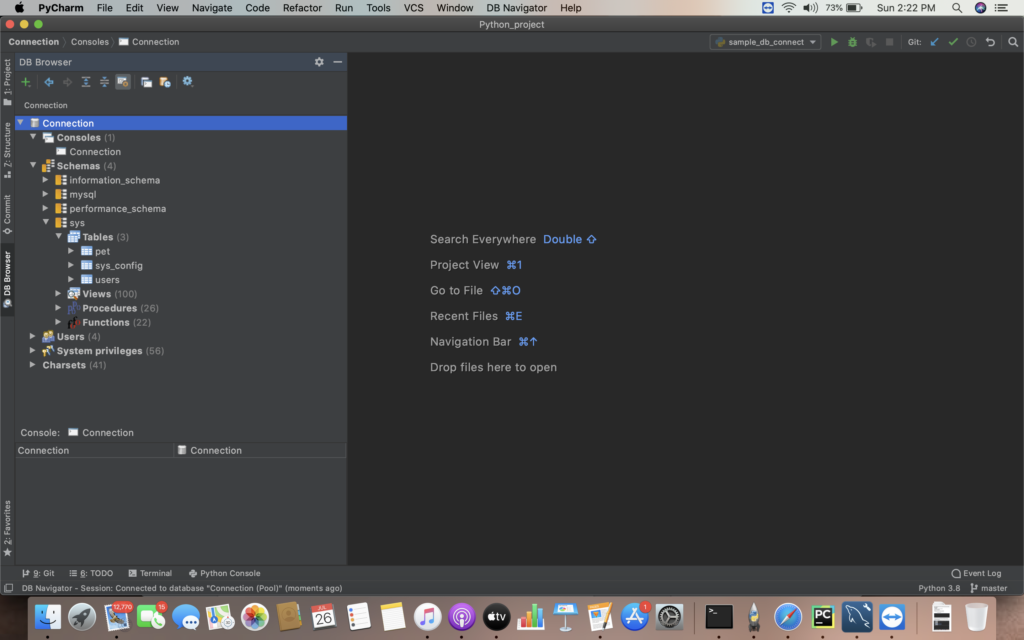
i) Go to View -> DB Browser . In the left pane you will be able to view the DB Browser section.
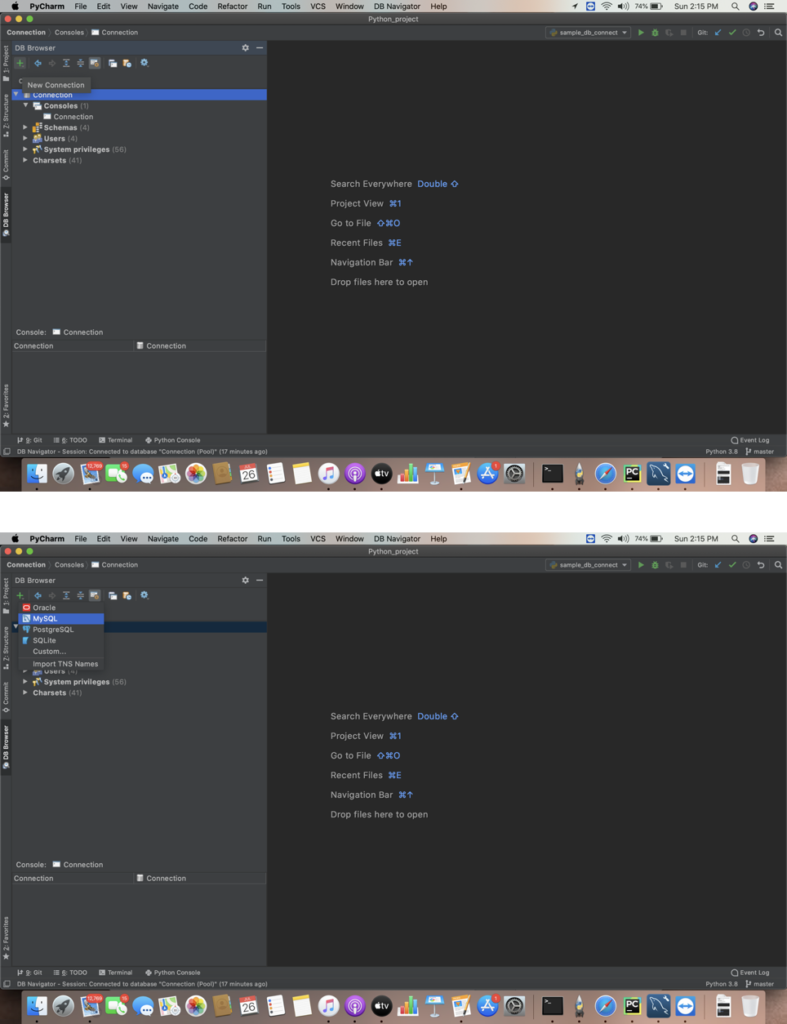
ii) Select “+” icon to Add new connection. Then select the database going to be accessed.
Here we are going to connect mysql database server. The DB – Navigator settings dialog box will pop up .
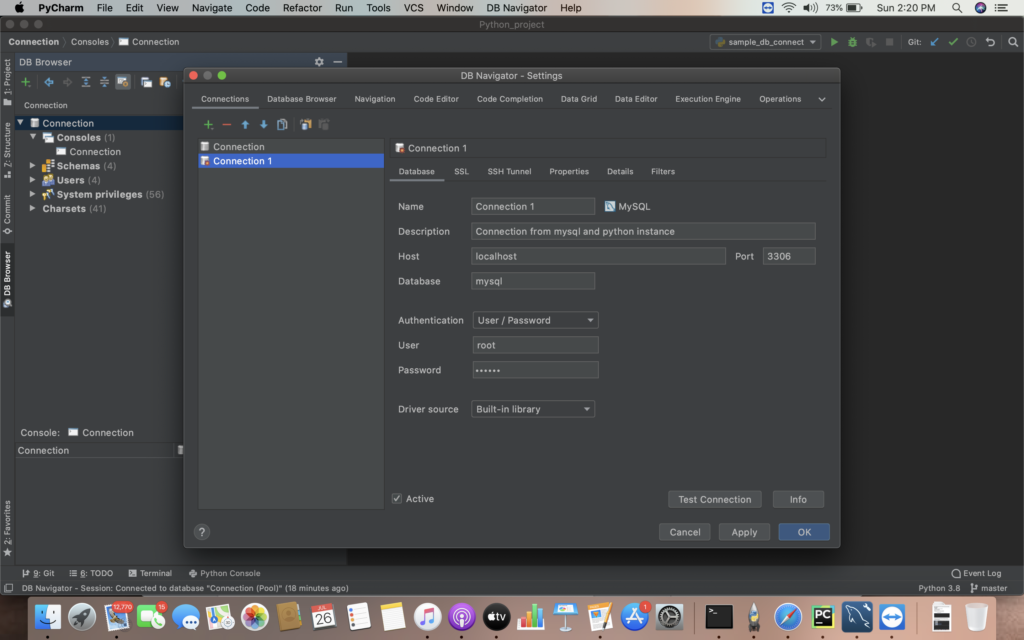
iii)Provide the mysql db connection details as below
* Hostname
* Port
* Username and Password
Then select Test Connection for success status and select OK.
iv) After the connection is set up . The database schema and corresponding table details will be shown in the DB Browser section in the left pane.