Numpy flatten() converts a multi dimensional array into ‘flattened’ one dimensional array. It returns a copy of the array in one dimension. Now let us see about numpy.ndarray.flatten().
numpy.ndarray.flatten()
Syntax:
ndarray.flatten(order = ‘C’)
Parameters:
- order: The order in which items from numpy array wil be used.
- ‘C’ – read items row wise i.e, using row major order
- ‘F’ – read items column wise i.e, column major order
- ‘K’ – read items in the order that occur in the memory
- ‘A’ – read items column wise only when the array is Fortran contiguous in memory.
- The default is ‘C’
Returns:
A copy of input array, flattened to 1D array.
Example:
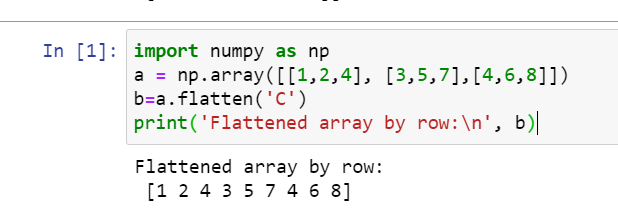
Flatten an array by row:
import numpy as np
a = np.array([[1,2,4], [3,5,7],[4,6,8]])
b=a.flatten('C')
print('Flattened array by row:\n', b)
Flatten an array by column:
import numpy as np
a = np.array([[1,2,4], [3,5,7],[4,6,8]])
b=a.flatten('F')
print('Flattened array by column:\n', b)

ndarray.flatten() returns the copy of the original array any changes made in flattened array will not be reflected in original array.
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
flat_array = a.flatten()
flat_array[2] = 10
print('Flattened 1D Numpy Array:')
print(flat_array)
print('Original Numpy Array')
print(a)
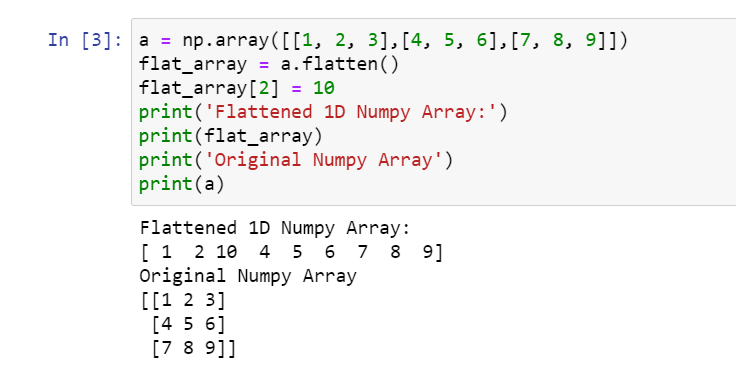
If you look the above code when we change the array value of index 2 as 10 i.e flat_array[2] = 10, it won’t affect the original array only the copy is changed.
To know more about numpy click here!