Pandas is an open source python library widely used for data science/ data analysis and machine learning tasks. Pandas stands for panel data, referring to tabular format.
Installing pandas:
pip install pandas
pip install numpy
This is because pandas is built on top of numpy which provides support for multi-dimensional arrays so it is always good to install with numpy. Pandas adopts many styles from numpy. The biggest difference is that pandas is for working with tabular, heterogeneous data whereas numpy is for working with homogeneous numerical data.
Pandas data structures:
Pandas have 3 data structures based on dimensionality.
- Series – one dimension
- DataFrame – two dimensions
- Panel – three dimensions
| Data Structure | Dimensions | Description |
| Series | 1 | 1D labeled homogeneous array, sizeimmutable. |
| Data Frames | 2 | General 2D labeled, size-mutable tabular structure with potentially heterogeneously typed columns. |
| Panel | 3 | General 3D labeled, size-mutable array. |
These data structures are built on top of numpy array. They are fast. Among these three, series and DataFrame are most widely used in data science and analysis tasks. In terms of Spreadsheet we can say series would be single column of spreadsheet, DataFrame is combination of rows and columns in a spreadsheet and panel is group of spreadsheet which have multiple DataFrames.
We can think of this as higher dimensional data structure is a container of lower dimensional data structure.
In this article we see about Pandas series datastructure.
Series Data Structure in Pandas:
One-dimensional array like data structure with some additional features. Series contains one axis, that is labelled as index of series. It is homogeneous and immutable array.
It consists of two components.
- One-dimensional data (values)
- Index
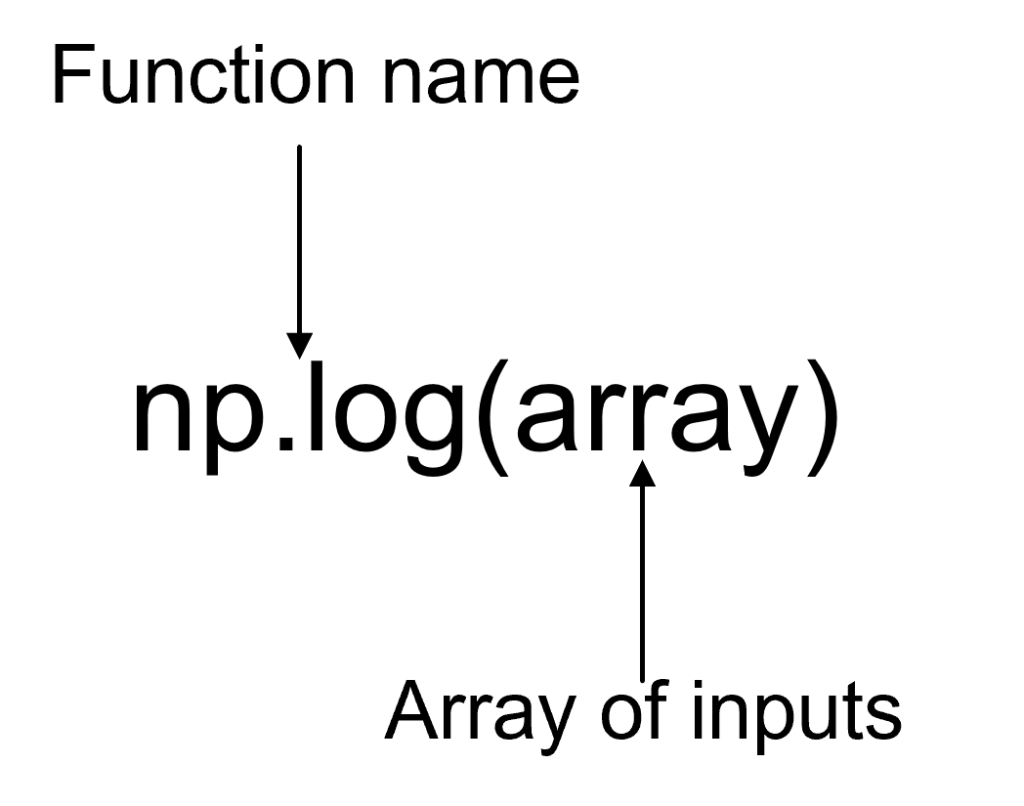
Syntax of series:
pandas. Series(data, index, dtype, copy)Parameters:
Data – takes forms like one dimensional ndarray, list, dictionary, scalar value.
Index – index values must be unique and hashable, same length as data. Default np.arange(n) if no index is passed.
Dtype– It is for data type. If none, data type will be inferred. Copy- copy data. Default false.
Example:
Creation of Series from ndarray:
import pandas as pd
import numpy as np
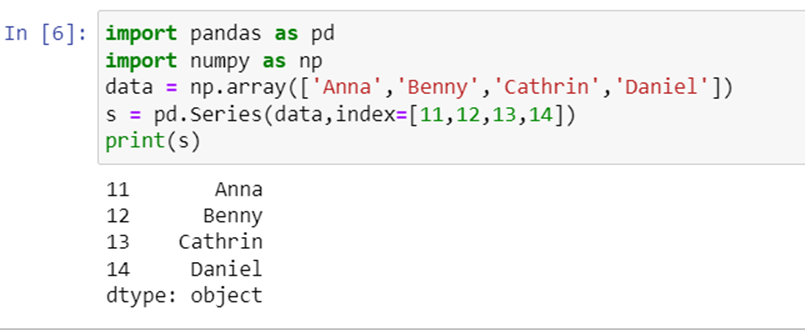
data = np.array(['Anna','Benny','Cathrin','Daniel'])
s = pd.Series(data,index=[11,12,13,14])
print(s)
#retrieving data with index
print(s[11])

Creation of Series from Dictionary:
import pandas as pd
import numpy as np
data = {'Anna' : 11, 'Benny' : 12, 'Cathrin' : 13, 'Daniel' : 14}
s = pd.Series(data)
print(s)
#accessing the data
print(s[0])


DataFrame:
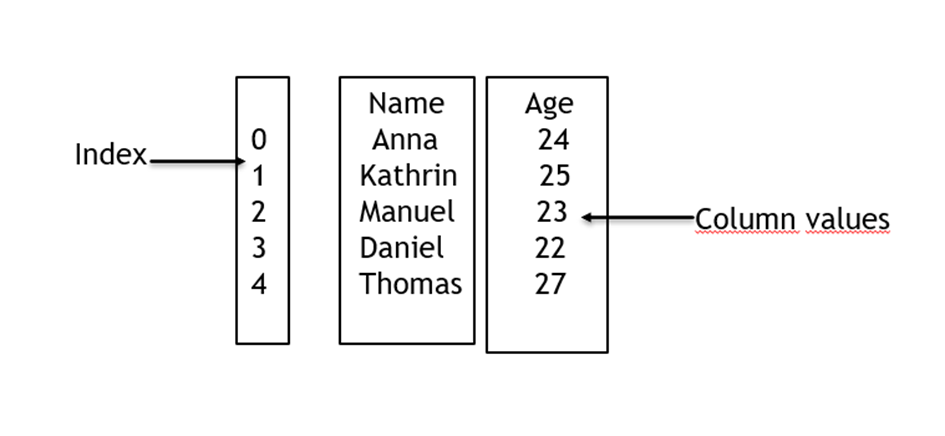
DataFrame is a two dimensional data structure having labelled axes as rows and columns. Here we have three components
- Data (heterogeneous data)
- Rows (horizontal)
- Columns (vertical)
Each column of DataFrame is a separate pandas Series. DataFrames are both value and size mutable.

Syntax:
pandas.DataFrame(data, index, columns, dtype, copy)DataFrame accepts many different types of arguments
- A two-dimensional ndarray
- A dictionary of dictionaries
- A dictionary of lists
- A dictionary of series
DataFrame creation using ndarray:
import pandas as pd
import numpy as np
a=np.array([['Anna',24],['Kathrin',25],['Manuel',23],['Daniel',22],['Thomas',27]])
s=pd.DataFrame(a,index=[1,2,3,4,5],columns=['Name', 'Age'])
print(s)

DataFrame creation using dictionary of dictionaries:
import pandas as pd
import numpy as np
a={'name':{11:'Anna',12:'Kathrin',13:'Manuel',14:'Daniel',15:'Thomas'},
'age': {11:24,12:25,13:23,14:22,15:27}}
df=pd.DataFrame(a)
print(df)
print(df.index)
print(df.values)
print(df.columns)


Panels:
Pandas panel data structure is used for working with three dimensional data. It can be seen as set of DataFrames. It is also heterogeneous data and value and size mutable.
Syntax:
pandas.Panel(data, items, major_axis, minor_axis, dtype, copy)
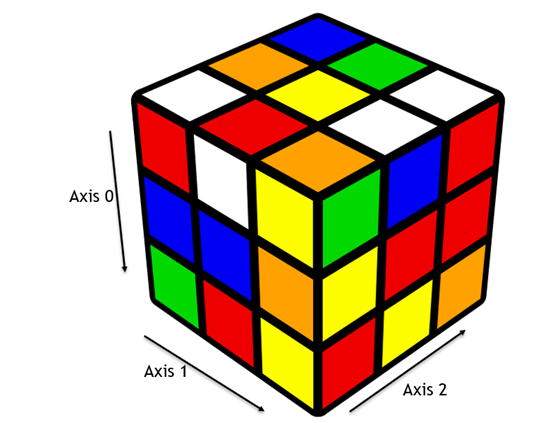
Items: Each item in this axis corresponds to one dataframe and it is axis 0
Major_axis: This contains rows or indexes of the dataframe and it is axis 1
Minor_axis: This contains columns or values of the dataframe and it is axis 2
We will learn more about DataFrames and panels data structures in coming articles.