Brief Introduction:
Recommender Systems have taken more and more place in our lives from the last few decades, with the rise of YouTube, Amazon, Netflix and many other such web streaming platform i.e., from e-commerce (suggest to buyers articles that could interest them) to online advertisement (suggest to users the right contents, matching their preferences), recommender systems are today unavoidable in our daily online journeys.
Recommender Systems are really critical in some industries as they can generate a huge revenue and also helps to stand out significantly from competitors. There are many success stories of recommender systems, to mention a few, a few years ago, Netflix organised challenges (the “Netflix prize”) with a prize of 1 million dollars to win, where the goal was to produce a recommender system that performs better than its own algorithm.
In this article, we will go through different paradigms of recommender systems. For each of them, we will present how they work, describe their theoretical basis and metrics to evaluate the performance of recommender system.
What is a Recommender System?
Recommender System captures the pattern of people’s behaviour and use it to predict what else they might want or like.
In a nut shell, recommender systems are algorithms hired to suggest relevant items to users (items being movies to watch, text to read, products to buy or anything else depending on industries).
Applications:-
- What to buy.
- Where to eat.
- Which job to apply to.
- Who you should be friends with.
- Personalize your experience on the web.
Advantages of Recommender Systems:-
- Broader exposure.
- Possibility of continual usage or purchase of products.
- Provides better experience.
Types:-
There are mainly three types:
i) Content-Based methods.
ii) Collaborative Filtering methods.
Further divided into two types
-> memory-based,
-> model-based
iii) Hybrid methods.
Implementing Recommender Systems:
Memory-based:-
Uses the entire user-item data set to generate a recommendation, uses statistical techniques to users or items.
example:- Pearson correlation, Cosine similarity, Euclidean distance etc.,
Model-based:-
Develops a model of users in an attempt to learn their preferences.
Models can be created using Regression, Clustering, Classification which are machine learning techniques.
Content-based Filtering:-
It recommends users based on the items they liked and recommends similar items to user that they might like it.


Figures out user’s favourite aspects of an item is, then recommends.
“Show me more of the same of what I have liked before” -> content-based
How it works?
Take a look at user’s data:
input user rating:
| A | 2 |
| B | 10 |
| C | 8 |
| Comedy | Adventure | Super hero | Sci-fic | |
| A | 0 | 1 | 1 | 0 |
| B | 1 | 1 | 1 | 1 |
| C | 1 | 0 | 1 | 0 |
Multiply input user ratings and genre matrix to get the user profile.
| Comedy | Adventure | Super hero | Sci-fic | |
| A | 0 | 2 | 2 | 0 |
| B | 10 | 10 | 10 | 10 |
| C | 8 | 0 | 8 | 0 |
| Comedy | Adventure | Super hero | Sci-fic |
| 18 | 12 | 20 | 10 |
| 0.3 | 0.2 | 0.33 | 0.16 |
With these information we are going to see how to predict for a new movie. Before that see the user profile.
| Comedy | Adventure | Super hero | Sci-fic | |
| User | 0.3 | 0.2 | 0.33 | 0.16 |
Movies matrix
| Comedy | Adventure | Super hero | Sci-fic |
| 1 | 1 | 0 | 1 |
| 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 0 |
Convert the above user input ratings to weighted movies matrix.
| 0.3 | 0.2 | 0 | 0.16 |
| 0 | 0 | 0.33 | 0 |
| 0.3 | 0 | 0.33 | 0 |
To get the recommendation matrix take the summation of individual row from the weighted movies matrix. This matrix would assist algorithm to make recommendations to the users by considering weighted average. Like if the average is less it would not recommend if average is high good chances for the item being recommended to the user.
| 0.66 |
| 0.33 |
| 0.63 |
Collaborative Filtering:-
Recommends what is popular among the user neighbour’s and recommends the same item to the user so they might like it.

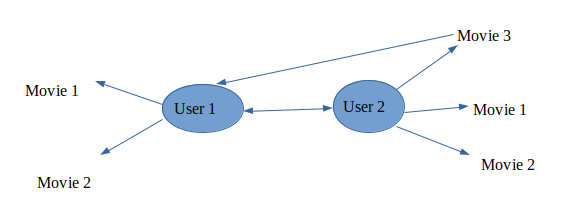
Makes recommendations based on users of same neighbourhood.
Two types:
i) User-based collaborative filtering: It is based on user’s neighbourhood.
ii) Item-based collaborative filtering: Based on item’s similarity.
Collaborative filtering makes recommendations based on users of same neighbourhood, with whom he/she shares a common preferences and vice-versa for item-based collaborative filtering.
Challenges of Collaborative filtering:
Data Sparsity:- Users in general rate only a limited number of items.
Cold start:- Difficulty in recommendation to new users or new items.
Scalability:- Increase in number of users or items.