So far we have learned how to use TensorFlow to implement a basic neural network, going up all the way to a basic Convolutional Neural Network. In this article, we’ll go much further by taking the ideas we’ve learned and applied them to a much bigger dataset of cats versus dogs on Kaggle. Yes, so we take the full Kaggle dataset of 25,000 cats versus dogs images. So we want to take a look at what it’s like to train a much larger data set, and that was like a data science challenge, not that long ago. Now, we’re going to learn that here, which I think is really helpful to get great results while operating on much bigger data sets.
What does it take to download a public dataset of the Internet, like cats versus dogs, and get a neural network to work on it? Data is messy, sometimes you find astonishing things like pictures of people holding cats or multiple cats or surprising things in data. For example, you might have some files that are zero length and they could be corrupt as a result. So it’s like using your Python skills, using your TensorFlow skills to be able to filter them out. Building a convolutional neural network to be able to spot things like we mentioned, a person holding a cat. So that’s some of the things we need to concentrate on. We’ll be using a very clean dataset that we’re using with cats versus dogs, but you’re going to hit some of those issues. In this article, you’ll learn the skills that you need to be able to deal with other datasets that may not be as clean as this one.
The reality is, there’s a lot of data cleaning, and having great tools to help with that data cleaning makes our workflow much more efficient. Definitely, in this article, you will get to practice all that, as well as train a pretty cool neural network to classify cats versus dogs. Please go ahead.
In this article, we’ll take our understanding of the Convolutional Neural Network to the next level by recognizing sophisticated real images of Cats and Dogs in order to classify an incoming image as one or the other. In particular, the handwriting recognition made your life a little easier by having all the images be the same size and shape, and they were all monochrome color. Real-world images aren’t like that — they’re in different shapes, aspect ratios, etc, and they’re usually in color!
So, as part of the task you need to process your data — not least resizing it to be uniform in shape.
You’ll follow these steps:
- Explore the Example Data of Cats and Dogs.
- Build and train a Neural Network to recognize the difference between the two.
- Evaluate Training and Validation accuracy.
Explore the Example Data
Let’s start by downloading our example data, a .zip of 2,000 JPG pictures of cats and dogs, and extracting it locally in /tmp.
NOTE: The 2,000 images used in this exercise are excerpted from the “Dogs vs. Cats” dataset available on Kaggle, which contains 25,000 images. Here, we use a subset of the full dataset to decrease training time.
!wget --no-check-certificate \
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip \
-O /tmp/cats_and_dogs_filtered.zipThe following python code will use the OS library to use Operating System libraries, giving you access to the file system, and the zip file library allowing you to unzip the data.
import os
import zipfile
local_zip = '/tmp/cats_and_dogs_filtered.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('/tmp')
zip_ref.close()The contents of the .zip are extracted to the base directory /tmp/cats_and_dogs_filtered, which contains train and validation subdirectories for the training and validation datasets, which in turn each contain cats and dogs subdirectories.
In short: The training set is the data that is used to tell the neural network model that ‘this is what a cat looks like’, ‘this is what a dog looks like’ etc. The validation data set is images of cats and dogs that the neural network will not see as part of the training, so you can test how well or how badly it does in evaluating if an image contains a cat or a dog.
One thing to pay attention to in this sample: We do not explicitly label the images as cats or dogs. If you remember with the handwriting example earlier, we had labeled ‘this is a 1’, ‘this is a 7’ etc. Later you’ll see something called an ImageGenerator being used — and this is coded to read images from subdirectories, and automatically label them from the name of that subdirectory. So, for example, you will have a ‘training’ directory containing a ‘cats’ directory and a ‘dogs’ one. ImageGenerator will label the images appropriately for you, reducing a coding step.
Let’s define each of these directories:
base_dir = '/tmp/cats_and_dogs_filtered'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
# Directory with our training cat/dog pictures
train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')
# Directory with our validation cat/dog pictures
validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')We can find out the total number of cat and dog images in the train and validation directories:
print('total training cat images :', len(os.listdir(train_cats_dir)))
print('total training dog images :', len(os.listdir(train_dogs_dir)))
print('total validation cat images :', len(os.listdir(validation_cats_dir)))
print('total validation dog images :', len(os.listdir(validation_dogs_dir)))For both cats and dogs, we have 1,000 training images and 500 validation images.
Now let’s take a look at a few pictures to get a better sense of what the cat and dog datasets look like. First, configure the matplot parameters:
%matplotlib inline
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
# Parameters for our graph; we'll output images in a 4x4 configuration
nrows = 4
ncols = 4
pic_index = 0 # Index for iterating over imagesNow, display a batch of 8 cat and 8 dog pictures. You can rerun the cell to see a fresh batch each time:
# Set up matplotlib fig, and size it to fit 4x4 pics
fig = plt.gcf()
fig.set_size_inches(ncols*4, nrows*4)
pic_index+=8
next_cat_pix = [os.path.join(train_cats_dir, fname)
for fname in train_cat_fnames[ pic_index-8:pic_index]
]
next_dog_pix = [os.path.join(train_dogs_dir, fname)
for fname in train_dog_fnames[ pic_index-8:pic_index]
]
for i, img_path in enumerate(next_cat_pix+next_dog_pix):
# Set up subplot; subplot indices start at 1
sp = plt.subplot(nrows, ncols, i + 1)
sp.axis('Off') # Don't show axes (or gridlines)
img = mpimg.imread(img_path)
plt.imshow(img)
plt.show()

It may not be obvious from looking at the images in this grid, but important note here, and a significant difference is that these images come in all shapes and sizes. These are color and in a variety of shapes. Before training a Neural network with them you’ll need to tweak the images. You’ll see that in the next section.
Ok, now that you have an idea of what your data looks like, the next step is to define the model that will be trained to recognize cats or dogs from these images
Building a Small Model from Scratch to Get to ~72% Accuracy
In the previous section, you saw that the images were in a variety of shapes and sizes. In order to train a neural network to handle them, you’ll need them to be in a uniform size. We’ve chosen 150×150 for this, and you’ll see the code that preprocesses the images to that shape shortly.
But before we continue, let’s start defining the model:
Step 1 will be to import tensorflow
Next, we will define a Sequential layer as before, adding some convolutional layers first. Note the input shape parameter this time. In the earlier example, it was 28x28x1, because the image was 28×28 in greyscale (8 bits, 1 byte for color depth). This time it is 150×150 for the size and 3 (24 bits, 3 bytes) for the color depth.
We then add a couple of convolutional layers as in the previous example and flatten the final result to feed into the densely connected layers.
Finally we add the densely connected layers.
Note that because we are facing a two-class classification problem, i.e. a binary classification problem, we will end our network with a sigmoid activation, so that the output of our network will be a single scalar between 0 and 1, encoding the probability that the current image is class 1 (as opposed to class 0).
model = tf.keras.models.Sequential([
# Note the input shape is the desired size of the image 150x150 with 3 bytes color
tf.keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# Flatten the results to feed into a DNN
tf.keras.layers.Flatten(),
# 512 neuron hidden layer
tf.keras.layers.Dense(512, activation='relu'),
# Only 1 output neuron. It will contain a value from 0-1 where 0 for 1 class ('cats') and 1 for the other ('dogs')
tf.keras.layers.Dense(1, activation='sigmoid')
])The model.summary() method call prints a summary of the NN
model.summary()
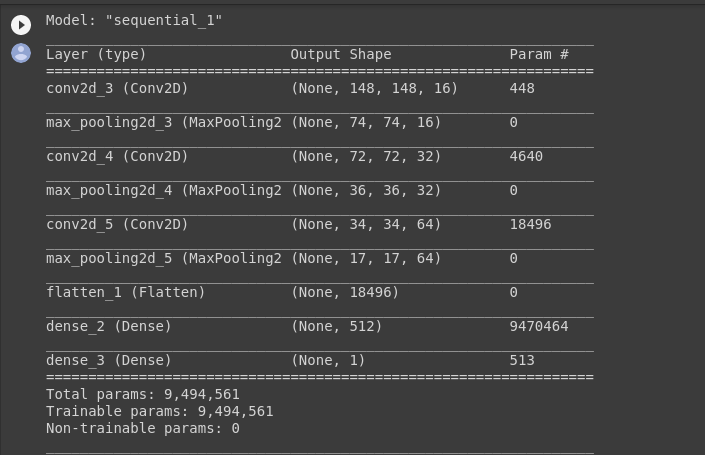
The “output shape” column shows how the size of your feature map evolves in each successive layer. The convolution layers reduce the size of the feature maps by a bit due to padding, and each pooling layer halves the dimensions.
Next, we’ll configure the specifications for model training. We will train our model with the loss because it’s a binary classification problem and our final activation is a sigmoid. We will use the rmsprop optimizer with a learning rate of 0.001. During training, we will want to monitor classification accuracy.
NOTE: In this case, using the RMSprop optimization algorithm is preferable to stochastic gradient descent (SGD), because RMSprop automates learning-rate tuning for us. (Other optimizers, such as Adam and Adagrad, also automatically adapt the learning rate during training, and would work equally well here.)
from tensorflow.keras.optimizers import RMSprop
model.compile(optimizer=RMSprop(lr=0.001),
loss='binary_crossentropy',
metrics = ['accuracy'])Data Preprocessing
Let’s set up data generators that will read pictures in our source folders, convert them to tensors, and feed them (with their labels) to our network. We’ll have one generator for the training images and one for the validation images. Our generators will yield batches of 20 images of size 150×150 and their labels (binary).
As you may already know, data that goes into neural networks should usually be normalized in some way to make it more amenable to processing by the network. (It is uncommon to feed raw pixels into a convent.) In our case, we will preprocess our images by normalizing the pixel values to be in the [0, 1] range (originally all values are in the [0, 255] range).
In Keras, this can be done via the keras.preprocessing.image.ImageDataGenerator class using the rescale parameter. This ImageDataGenerator the class allows you to instantiate generators of augmented image batches (and their labels) via .flow(data, labels) or .flow_from_directory(directory). These generators can then be used with the Keras model methods that accept data generators as inputs: fit, evaluate_generator, and predict_generator.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# All images will be rescaled by 1./255.
train_datagen = ImageDataGenerator( rescale = 1.0/255. )
test_datagen = ImageDataGenerator( rescale = 1.0/255. )
# --------------------
# Flow training images in batches of 20 using train_datagen generator
# --------------------
train_generator = train_datagen.flow_from_directory(train_dir,
batch_size=20,
class_mode='binary',
target_size=(150, 150))
# --------------------
# Flow validation images in batches of 20 using test_datagen generator
# --------------------
validation_generator = test_datagen.flow_from_directory(validation_dir,
batch_size=20,
class_mode = 'binary',
target_size = (150, 150))Training
Let’s train on all 2,000 images available, for 15 epochs, and validate on all 1,000 test images.
Do note the values per epoch.
You’ll see 4 values per epoch — Loss, Accuracy, Validation Loss and Validation Accuracy.
Loss and Accuracy are a great indication of the progress of training. It’s making a guess as to the classification of the training data, and then measuring it against the known label, calculating the result. Accuracy is the portion of correct guesses. The Validation accuracy is the measurement with the data that has not been used in training. As expected this would be a bit lower. You’ll learn about why this occurs in the section on overfitting later in this course.
history = model.fit(train_generator,
validation_data=validation_generator,
steps_per_epoch=100,
epochs=15,
validation_steps=50,
verbose=2)
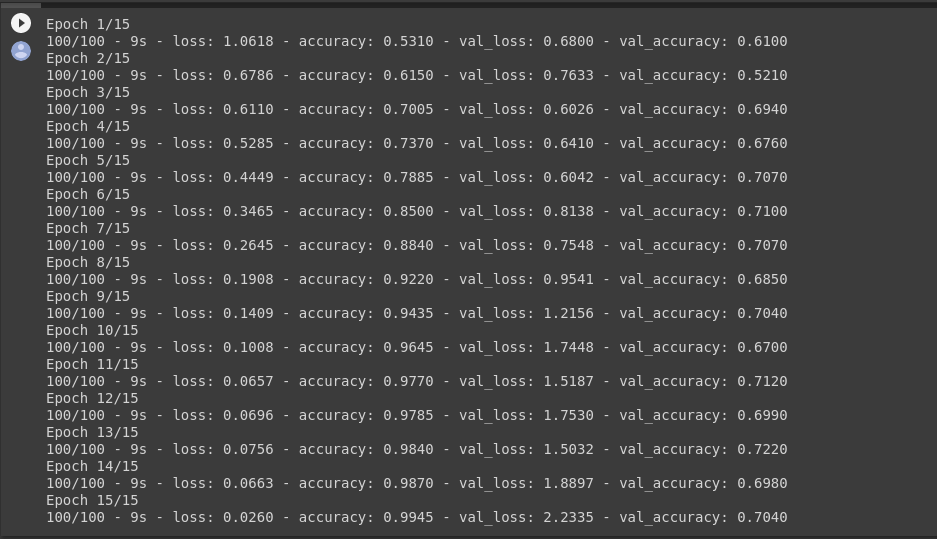
Evaluating Accuracy and Loss for the Model
Let’s plot the training/validation accuracy and loss as collected during training:
#-----------------------------------------------------------
# Retrieve a list of list results on training and test data
# sets for each training epoch
#-----------------------------------------------------------
acc = history.history[ 'accuracy' ]
val_acc = history.history[ 'val_accuracy' ]
loss = history.history[ 'loss' ]
val_loss = history.history['val_loss' ]
epochs = range(len(acc)) # Get number of epochs
#------------------------------------------------
# Plot training and validation accuracy per epoch
#------------------------------------------------
plt.plot ( epochs, acc )
plt.plot ( epochs, val_acc )
plt.title ('Training and validation accuracy')
plt.figure()
#------------------------------------------------
# Plot training and validation loss per epoch
#------------------------------------------------
plt.plot ( epochs, loss )
plt.plot ( epochs, val_loss )
plt.title ('Training and validation loss' )
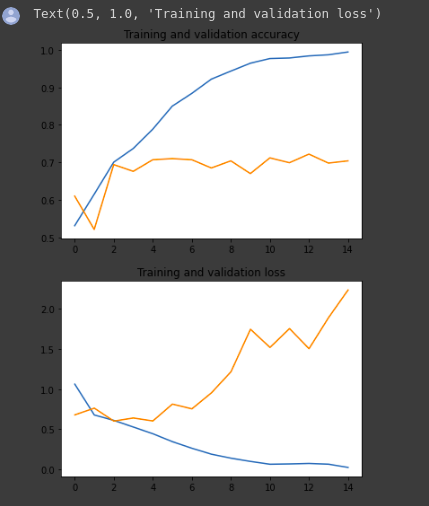
As you can see, we are overfitting like it’s getting out of fashion. Our training accuracy (in blue) gets close to 100% (!) while our validation accuracy (in green) stalls as 70%. Our validation loss reaches its minimum after only five epochs.
Since we have a relatively small number of training examples (2000), overfitting should be our number one concern. Overfitting happens when a model exposed to too few examples learns patterns that do not generalize to new data, i.e. when the model starts using irrelevant features for making predictions. For instance, if you, as a human, only see three images of people who are lumberjacks, and three images of people who are sailors, and among them, the only person wearing a cap is a lumberjack, you might start thinking that wearing a cap is a sign of being a lumberjack as opposed to a sailor. You would then make a pretty lousy lumberjack/sailor classifier.
Overfitting is the central problem in machine learning: given that we are fitting the parameters of our model to a given dataset, how can we make sure that the representations learned by the model will be applied to data never seen before? How do we avoid learning things that are specific to the training data?
In the next exercise, we’ll look at ways to prevent overfitting in the cat vs. dog classification model.