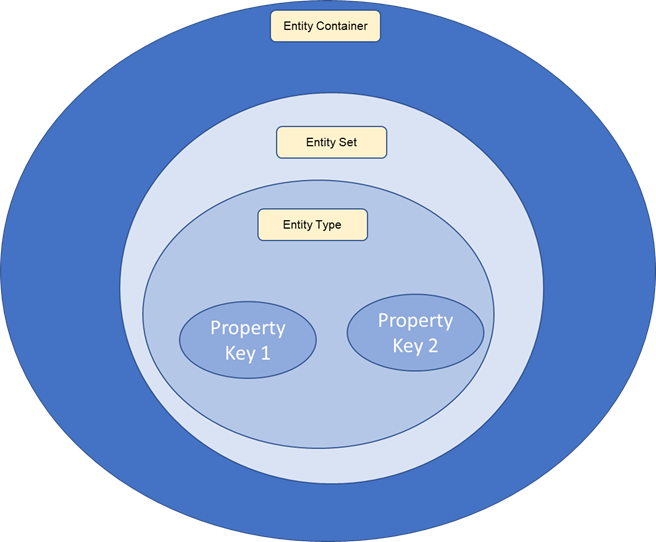
In Python we have 4 built-in data structures which covers 80% of the real-world data structures. These are classified as non-primitive data structures because they store a collection of values in various format than a single value. Some can store data structures within data structures, creating depth and complexity.

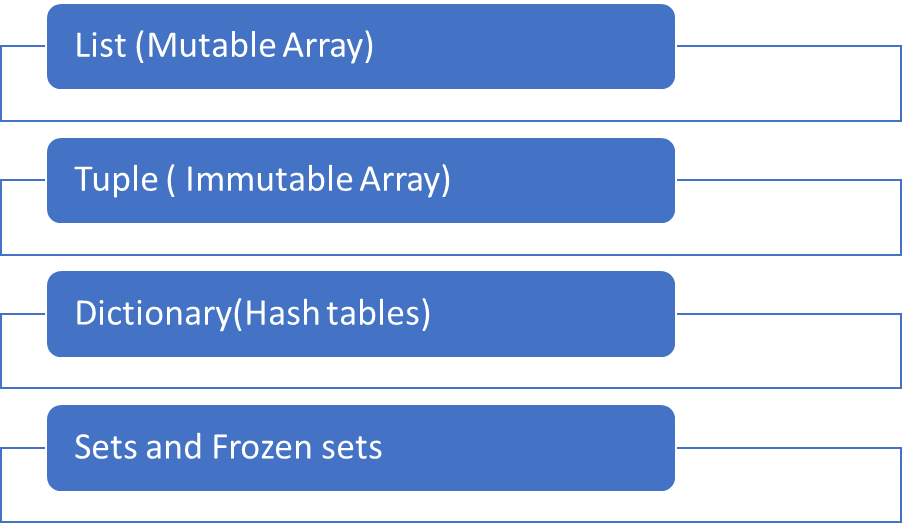
Built-in data structures are predefined data structures that come along with Python. Lists and tuples are ordered sequence of objects. Unlike strings that contain only characters, lists and tuples can contain any type of objects.
- List and tuples are like arrays.
- Tuples like strings are immutables.
- Lists are mutables so they can be converted after their creation.
- Sets are mutable unordered sequence of unique elements whereas frozensets are immutable sets
Lists are enclosed in brackets: l =[1,2,’a’]
Tuples are enclosed in parentheses: t=(1,2,’a’)
Dictionaries are built with curly brackets: d= {‘a’:1, ‘b’:2}
Set are built with curly brackets: s= {1,2,3}
Tuples are faster and consume less memory.
Lists:
They are used to store data of different data types in a sequential manner. It stores heterogeneous data in sequential order. There are two types of indexing: positive index(most common method) and negative index.
Indexing:
Positive Index means every element has an index that starts from 0 and goes until last element.
Negative Index starts from -1 and it starts retrieving from last element.


Slicing:
In Python List slicing is the most common practice to solve problems efficiently. If we want to use a range of elements from the list we can access those range with slicing and the operator used is colon (:)
Syntax:
List [start:end:index jump]

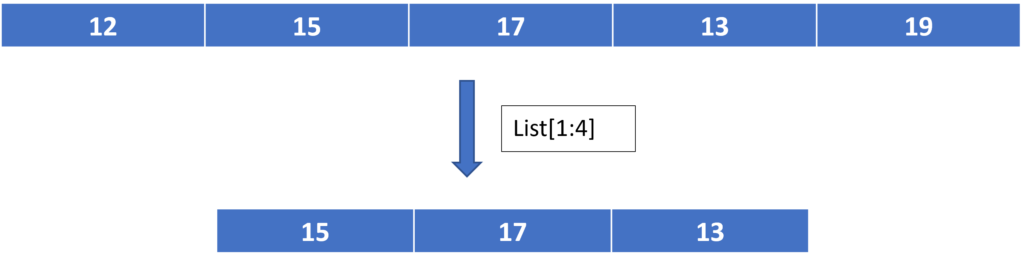

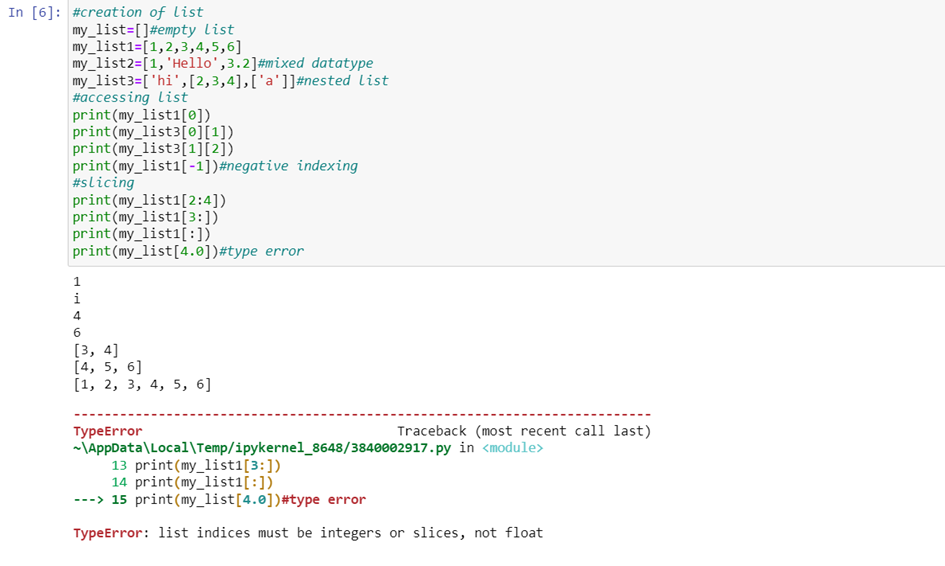
Type error occurs when data types other than integer are used to access like in our example float is used. Index error occurs when we try to access indexes out of range.
List Functions:

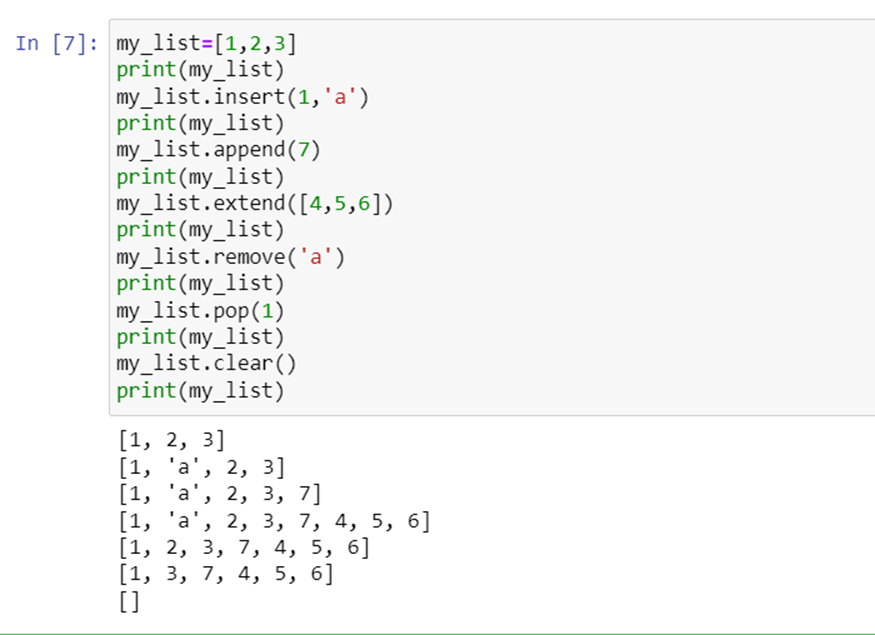
Let us see some functions in the sample code snippet:

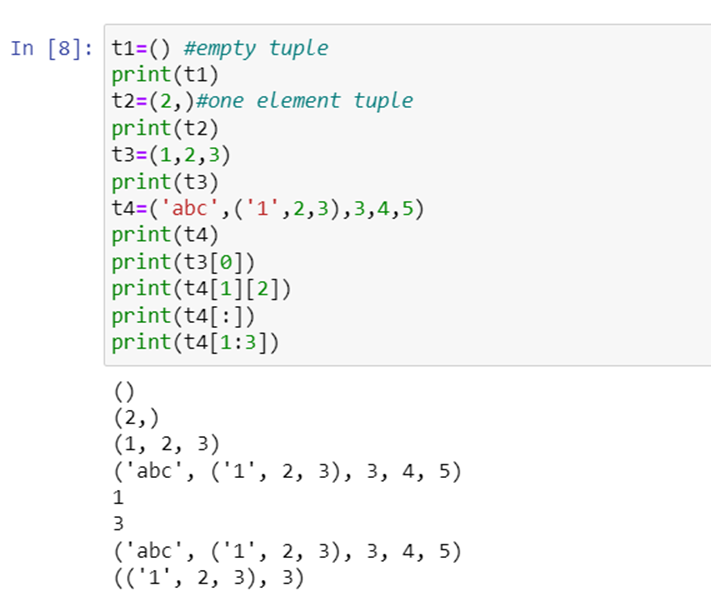
Tuple:
Tuples are same as list but the only exception is that data cannot be changed once entered into the tuple. They are immutable. Since it is immutable the length is fixed, to grow or shrink a tuple we need to create a new tuple. Like list tuple also has some methods

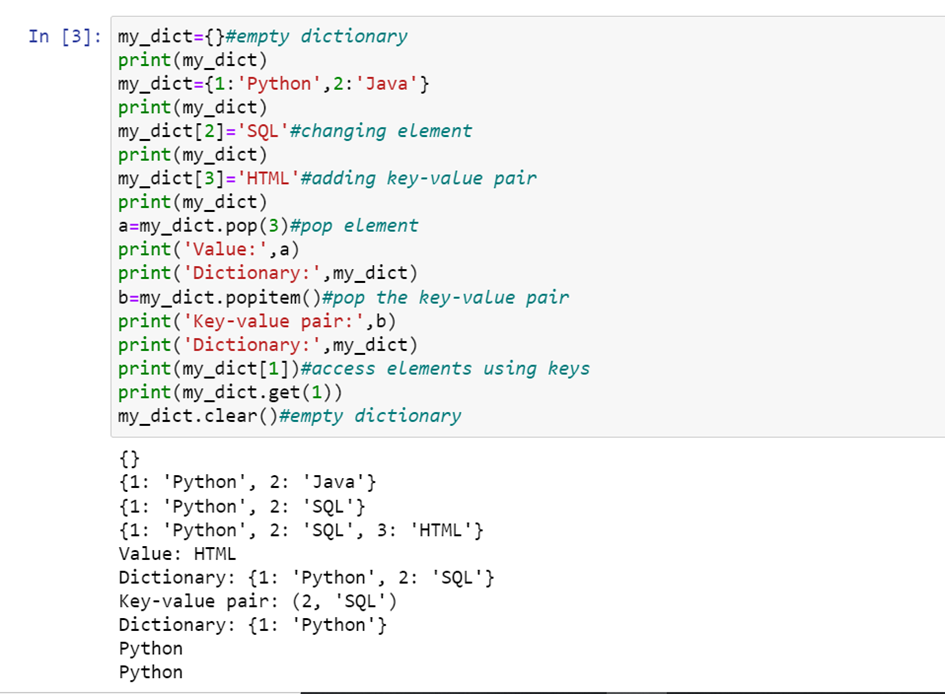
Dictionaries:
Dictionary is a datastructure which stores the data in the form of key:value pairs. Dictionary is a collection of ordered, changeable and does not allow duplication. Key-value is provided in dictionary to make it more optimized. For better understanding, dictionary can be compared to a telephone directory with tens of thousands of names and phone numbers. Here the constant values are names and phone numbers these are the keys and the various names and phone numbers fed to the keys are called values.

Sets:
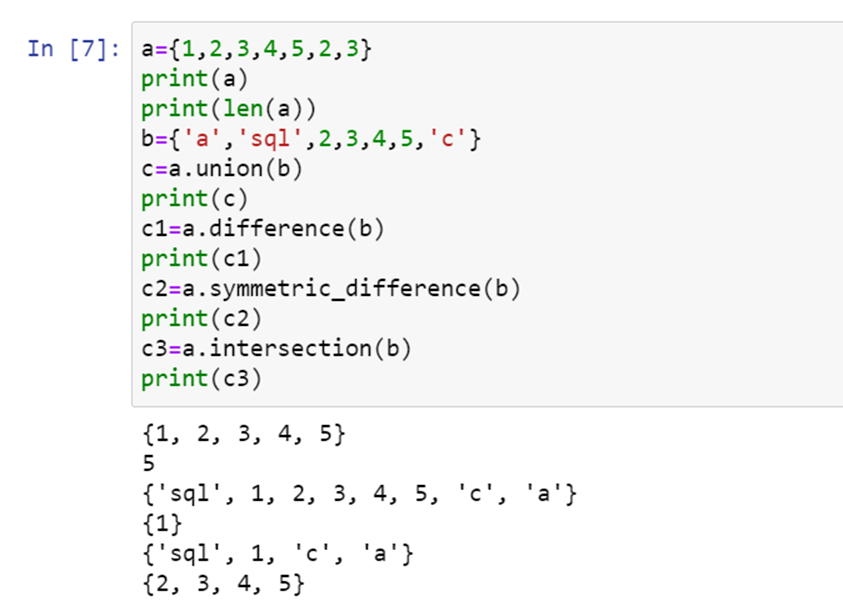
Sets are a collection of unordered elements that are unique. Even if the data is repeated more than once it will be entered in the set only once. It is same as arithmetic sets.
Sets are created same way as in dictionary by using curly brackets but instead of key value pairs we pass values directly.
Now let us see a sample code snippet with set creation and its operations such as union, intersection, difference, symmetric_difference
- Union combines both sets
- Intersection finds the elements present in both sets
- Difference deletes the elements present in both sets and outputs the elements present only in the set
- Symmetric_difference is same as difference but outputs the data which is remaining in both sets.

These are all the four basic data structures one need to know while learning python programming.